大数据采集工具
- Chukwa
- Flume
- Scrible
- Kafka
Kafka介绍
Apache Kafka被设计成能够高效地处理大量实时数据,其特点是快速的、可扩展的、分布式的,分区的和可复制的。Kafka是用Scala语言编写的,虽然置身于Java阵营,但其并不遵循JMS规范。
- 话题
- 生产者
- 消费者
- 代理
噪声
噪声处理
- 分箱
- 回归
- 聚类
数据挖掘常用算法
广义角度
- 分类
- 聚类
- 估值
- 预测 机器学习 : 决策树
聚类算法
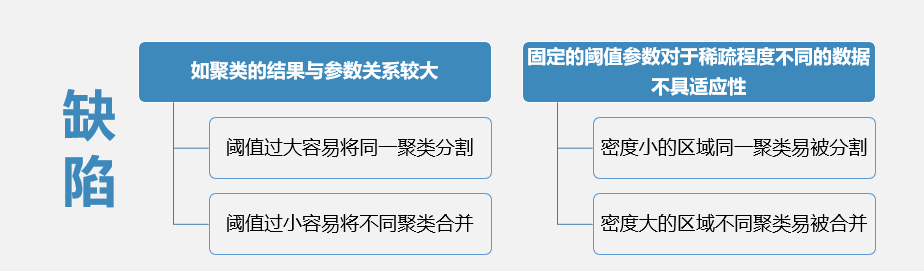
基于密度的聚类算法
基于密度聚类的经典算法DBSCAN(Density-Based Spatial Clustering of Application with Noise,具有噪声的基于密度的空间聚类应用)是一种基于高密度连接区域的密度聚类算法。 DBSCAN的基本算法流程如下:从任意对象P 开始根据阈值和参数通过广度优先搜索提取从P 密度可达的所有对象,得到一个聚类。若P 是核心对象,则可以一次标记相应对象为当前类并以此为基础进行扩展。得到一个完整的聚类后,再选择一个新的对象重复上述过程。若P 是边界对象,则将其标记为噪声并舍弃
预测模型
预测分析是一种统计或数据挖掘解决方案,包含可在结构化与非结构化数据中使用以确定未来结果的算法和技术,可为预测、优化、预报和模拟等许多其他相关用途而使用。
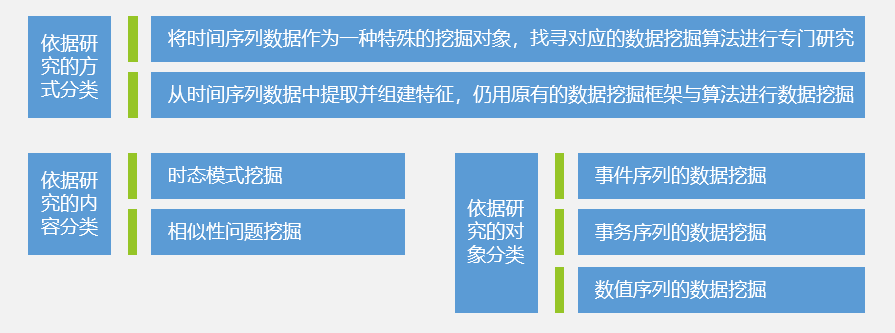
时间序列预测是一种历史资料延伸预测,以时间序列所能反映的社会经济现象的发展过程和规律性,进行引申外推预测发展趋势的方法。
时间序列预测及数据挖掘分类
柱状图作用
传统柱状图一般用于表示客观事物的绝对数量的比较或者变化规律,用于显示一段时间内数据的变化,或者显示不同项目之间的对比,分为:二维簇状柱形图、二维堆积柱形图、二维百分比堆积柱形图。
三维柱状图的可视化效果更佳直观,而且能够在第三个坐标轴显示三维数据。三维柱状图采用柱体来量化数据,同时对柱体可以采用不用的颜色编码,来表述不同的变量
可视化
- 沙盒分析法
- 认知作业法
- 顺序模式法
- 协同多视图法
云渲染
云渲染(Rendering Cloud)的概念源自于云计算,是云计算在渲染领域的应用。云渲染是指将由客户端处理的图形渲染转移至服务器端(云端)的技术;云渲染技术的应用,可以使客户端简化,只需要具备显示能力以及网络接入能力,就可以享有顶级的图形处理能力,使同一图形可以呈现在众多终端设备上。
云渲染系统的组成包括以下
- 图形资源工具: 按指定格式输出可视化图形资源的工具,用户可以通过该工具生成可视化图形并提交至渲染云;
- 渲染云: 由存储服务器、渲染脚本解析服务器、渲染服务器、图形压缩服务器共同组成
- 终端: 终端为渲染请求的提交者和渲染结果的接收者,在需要渲染服务时,终端将向渲染云提交请求,收到可视化渲染结果后,终端将负责最终显示给用户。
可视化交互方法五大技术
- 平移 缩放
- 概览 细节
- 动态过滤
- 焦点 上下文
- 多视图关联协调
深度学习
- CNTK
- MXnet
- THeano
- Torch
- Deeplearning4j
CNTK 的特点
- 训练和测试多种神经网络的通用解决方案。
- 用户使用一个简单的文本配置文件指定一个网络。
- 尽可能无缝地把很多计算在一个GPU上进行。
- 自动计算所需要的导数,网络是由许多简单的元素组成。
- 通过添加少量的C ++代码来实现必需块的扩展。
MXnet 的特点
- (1)其设计说明可以被重新应用到其他深度学习项目中。
- (2)任意计算图的灵活配置。
- (3)整合了各种编程方法的优势,最大限度地提高灵活性和效率。
- (4)轻量、高效的内存,以及支持便携式的智能设备,如手机等。
- (5)多GPU扩展和分布式的自动并行化设置。
- (6)支持Python、R、C++和Julia。
- (7)对云计算友好,直接兼容S3、HDFS和Azure。
Torch 的特点
- 很多实现索引、切片、移调的程序。
- 通过LuaJIT的C接口。
- 快速、高效的GPU支持。
- 可嵌入、移植到iOS、Android和FPGA的后台。
网页排序四种算法
- 访问量
- 词频统计词语位置加权
- 基于链接分析
- 基于智能化的排序算法
推荐系统:大题 p19
广告评估,点击率
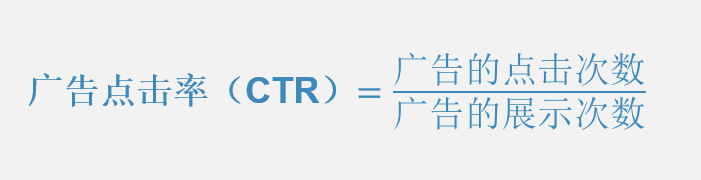
评价一个网络广告推广效果好坏的测量指标是多样的,例如,可以通过广告展示量、广告点击量、广告到达率、广告转化率等指标进行评价。其中,广告点击率(Click-Through-Rate,CTR)是当前最为普遍的评价方式,是反应网络广告推广质量最直接的量化指标。广告点击率的计算公式为如下:
广告的影响
- 广告自身的影响
- 上下文
- 广告浏览者的影响
大数据应用
略
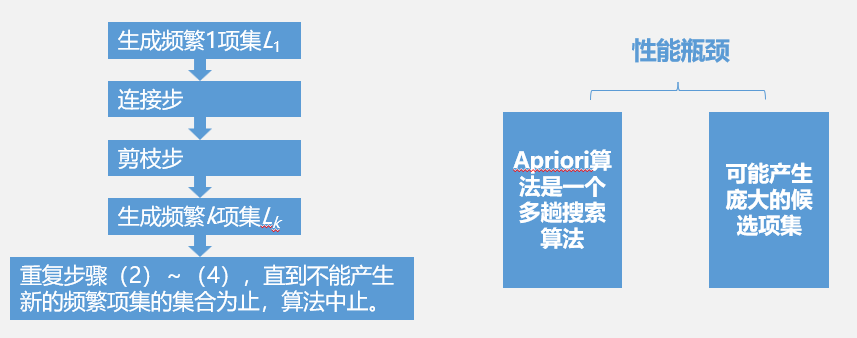
Apriori算法
Apriori算法基于频繁项集性质的先验知识,使用由下至上逐层搜索的迭代方法,即从频繁1项集开始,采用频繁k项集搜索频繁k+1项集,直到不能找到包含更多项的频繁项集为止。